

We ship AI tooling faster than most companies ship meeting notes. Our entire team runs on the Tenzir Claude Marketplace: 10+ plugins covering everything from TQL development to C++ conventions to documentation workflows. It's not a side project. It's how we build software now.
So when we say "we did MCP wrong," we're not apologizing. We're iterating. Fast.
Here's what happened: we built our MCP server with careful architecture, structured tools, intelligent prompting. We wrote blog posts about empowerment over entrapment, about flipping power dynamics, about AI-catalyzed pipelines. We shipped it. Customers used it.
Then we measured it against our own Claude Code skills: the same underlying workflows, delivered differently and discovered we'd been paying double for the privilege of over-engineering.
The good news: when you move this fast, course corrections are cheap.
The confession
Here's the uncomfortable truth: most of our MCP tools are thin wrappers around command-line invocations. Our run_pipeline tool, the one we built custom infrastructure for, does the same thing as typing tenzir "your pipeline here" in a terminal. Our package_create tool? It makes a few directories and writes some files. Our docs_read tool is more nuanced—it bundles documentation locally for offline use, which matters—but for cloud-connected workflows, it's solving a problem that doesn't exist.
We spent months building "structured tools with intelligent prompting" when, for online use cases, we could have just... let the model type commands into a terminal like any developer would.
We ran an experiment last week. Same task, creating a new TQL package with a parser that deconstructs unstructured logs into "clean" (nulls removed) atomic data points. Two approaches:
MCP: Our carefully crafted custom tools with RAG-enhanced documentation and deterministic validation
Skills: Our TQL plugin from the Claude Marketplace, the same workflow knowledge, delivered as readable instructions that Claude Code executes using built-in tools
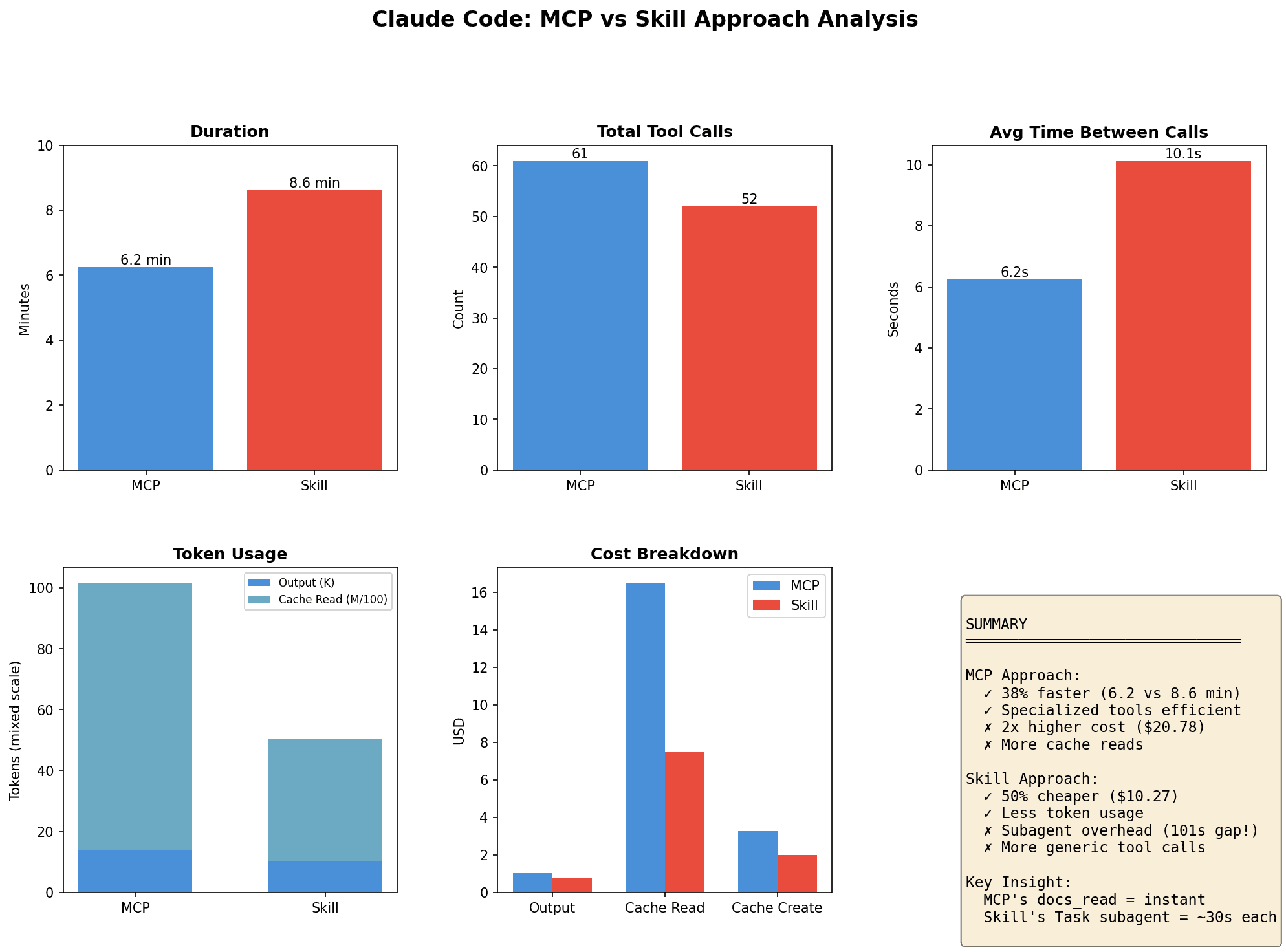
The numbers don't lie
Same task. Same outcome. Two very different costs.
Metric | MCP | Skills | Winner |
|---|---|---|---|
Duration | 6.2 min | 8.6 min | MCP |
Tool calls | 61 | 52 | Skills |
Estimated cost | $20.78 | $10.27 | Skills |
MCP is faster, we'll give it that. But it costs twice as much to run. For a single task.
The shape of each approach tells the story immediately:
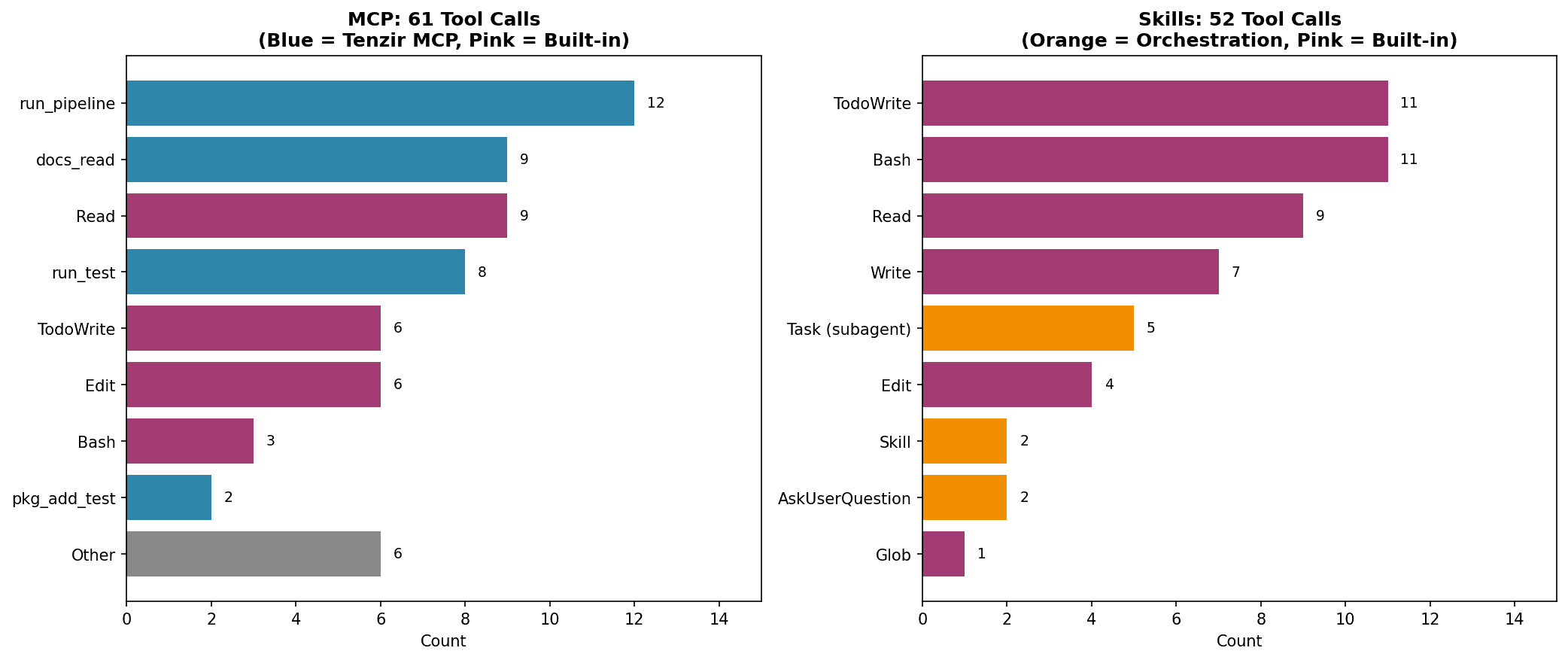
MCP (left) leans heavily on our custom Tenzir tools—the blue bars. run_pipeline, docs_read, run_test. These are purpose-built infrastructure. Skills (right) uses almost entirely generic capabilities—the pink bars. Bash, Write, Read. Plus orchestration tools in orange: Task for delegation, Skill for loading instructions, AskUserQuestion for clarification.
Let's break down what happened. The MCP approach made 61 tool calls—each one an interaction between the AI and our custom infrastructure. Of those, 35 were our specialized Tenzir tools:
12×
run_pipeline: executing TQL queries9×
docs_read: fetching documentation pages8×
run_test: running validation tests2×
package_add_test: adding test files4× other package scaffolding tools
The Skills approach? It delegated work to 5 sub-agents (think: junior assistants given specific tasks), ran 11 shell commands, read 9 files, and wrote 7 files. Generic capabilities. No custom infrastructure. Just an AI that knows how to use a computer like a developer would.
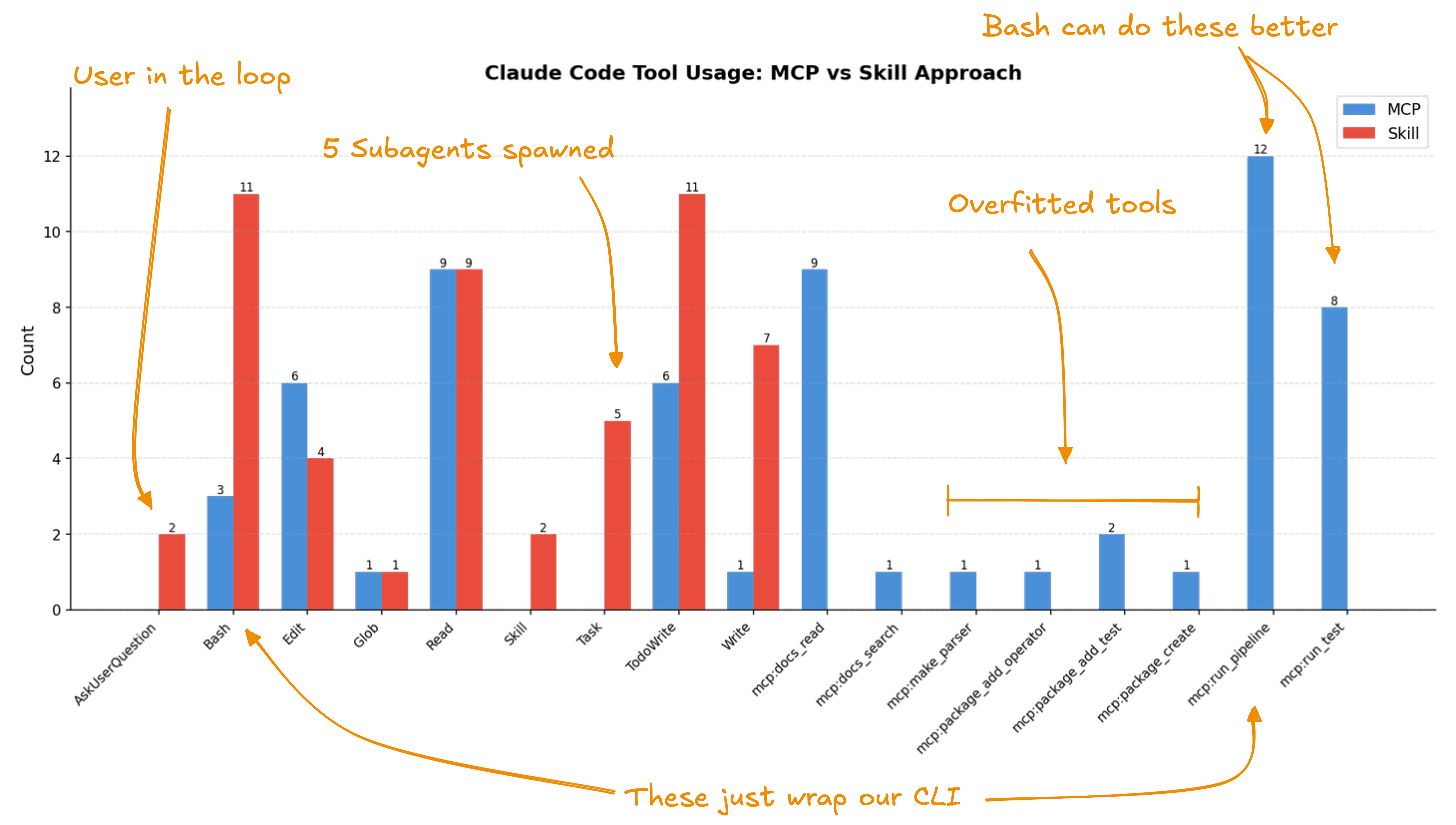
The annotated view makes the waste obvious. On the right: "overfitted tools," custom MCP infrastructure that wraps command-line invocations we could have just... run directly. The mcp:run_pipeline and mcp:run_test tools do provide real value (sandboxed execution). But mcp:docs_read, mcp:package_*, and mcp:make_parser? Bash can do these better.
On the left: the Skills approach stayed in the loop. It asked clarifying questions (AskUserQuestion), something our rigid MCP tools never did. The AI collaborated with the user instead of blindly executing a pre-scripted workflow.
Notice what's equal: both approaches read the same number of files (9× Read). Both needed to inspect existing code and documentation. The difference is everything else.
Where the time goes
The Skills approach was 38% slower. Why? Delegation overhead. Each time the AI hands off work to a sub-agent, the sub-agent needs to understand the context—what's the goal, what's been done so far, what tools are available. That context-building takes 30-100 seconds per delegation. One gap between tasks was 101 seconds of pure thinking time.
MCP doesn't have this problem because our tools are synchronous—call docs_read, get documentation back instantly. No context juggling. No delegation. Fast because it's simple.
But here's the thing: that "simple and fast" approach burns through tokens. Lots of tokens.
A quick primer on AI costs: Large language models charge by "tokens," roughly, chunks of text they read and write. Reading costs less than writing. But there's a third category: "cached" tokens, which are previously-seen context that gets reused. Our MCP tools stuff enormous amounts of structured data into the AI's context window (JSON schemas, OCSF metadata, documentation chunks) and that all gets read and cached, repeatedly.
The MCP session consumed 8.8 million cached tokens versus 4.0 million for Skills. More than double. Every one of our structured tool responses bloated the context window, and the AI had to process it all, every single turn.
The irony (and the lesson)
We wrote about how "LLM capabilities are advancing rapidly, what's state-of-the-art today will be commodity in six months." We warned against "model lock-in" and "building on quicksand."
Turns out, that advice applied to our own tools too.
Our make_parser guide tool is essentially a prompt template with workflow orchestration baked in. It tells the AI: "First, read the documentation. Then analyze the log. Then generate code. Then test it." When we built it, this structure improved reliability. Models needed the guidance.
Six months later? Models got better at figuring this out themselves. Modern AI doesn't need us to dictate the order of operations. It can read docs, try things, iterate on failures. The overhead of our "intelligent orchestration" became pure cost, we were paying for scaffolding the AI no longer needs.
This is what moving fast looks like: you build for today's models, measure against tomorrow's, and adapt. The alternative, building nothing until you're certain, means building nothing.
What actually matters
Let's revisit what we wrote in November:
"The MCP server takes a different approach: structured tools with intelligent prompting. Instead of dumping everything into a prompt and hoping, we provide focused tools..."
We weren't wrong about the goal. We were wrong about the mechanism.
What actually matters:
Documentation accessibility: The model needs to know TQL syntax and OCSF schemas. For online workflows, it doesn't need a custom
docs_readtool, it needs a searchable doc site. But for offline and on-prem deployments, bundled documentation is genuinely valuable. Context matters.Execution feedback: The model needs to test its generated code. But
run_pipelineis justtenzir "..."with JSON output. The model can invoke that directly.Deterministic validation: This is where we got it right.
ocsf::castandocsf::deriveprovide guarantees that prompt engineering can't. The validation lives in the engine, where it belongs.
The rest? Scaffolding. Wrappers. Ceremony.
The new approach
We're not killing the MCP server. The tools that provide genuine capabilities—real-time OCSF schema queries, deterministic validation, execution sandboxing—those stay. They add value the model can't replicate.
But the orchestration tools? The "high-level guides" that tell the model how to think? Those are getting deprecated. The model doesn't need a make_parser tool that sequences 12 other tool calls. It can sequence tool calls itself. That's literally what it's good at.
Here's what we're moving toward:
Minimal tools. If a shell command can do it, let the AI run a shell command. Every custom tool needs to justify its existence against "what if the AI just typed this into a terminal?"
Model-driven workflows. Stop encoding step-by-step workflows into our tools. Let the AI figure out the workflow. Give it capabilities, not recipes.
Documentation as interface. Instead of force-feeding context into every tool call, maintain excellent documentation that AI models can search and read—the same way a human developer would. Our docs are already good. Let's trust the AI to use them.
Validation at the boundaries. Keep deterministic validation in the engine. Our ocsf::cast operator catches schema errors that no amount of AI prompting will prevent. That's real value, the kind the AI can't replicate.
What this tells us
We built MCP tools for a world where models needed more structure than they actually need now. We optimized for reliability at the cost of efficiency. For cloud-connected workflows with frontier models, that tradeoff no longer makes sense.
The Skills approach (our TQL plugin running on Claude Code with basic file and shell access) produced a working package at half the cost. Slower, yes. But when you're paying per token, "slower but half price" wins.
The real insight: tools should match the environment. Our Claude Marketplace plugins run against frontier models with internet access, they can afford to be minimal. Our MCP server runs against local models in constrained environments, it needs to bundle more. Same knowledge, different delivery.
We gave big speeches about not being gatekeepers. Then we gatekept the model's access to our own CLI behind eighteen structured tools. Now we're fixing it.
What we're shipping
Next release refocuses the MCP server on what MCP does best: external capabilities.
Keep what models can't do themselves: sandboxed execution, test frameworks, schema validation, pipeline orchestration
Remove workflow logic: the "guides" and orchestration tools that tell models how to think
Separate skills from MCP: workflow knowledge lives in documentation, accessible anywhere
The MCP server becomes a capability layer. Skills remain documentation. Models figure out the rest.
The future: MCP for external capabilities
So if our MCP tools are mostly wrappers, why not kill the MCP server entirely?
Because MCP is genuinely good at one thing: interfacing with external systems.
What MCP is for
MCP shines when it connects AI to capabilities outside the model's reach, things that require stateful connections to running infrastructure:
Orchestrating data flows across distributed Tenzir nodes
Managing long-running pipelines that outlive a single conversation
Querying live system state across a fleet of deployed nodes
Coordinating multi-step workflows that span services
These aren't things a model can do by typing shell commands. They require persistent connections, authentication, state management. That's MCP's job.
What MCP is not for: wrapping CLI invocations, fetching documentation, or "guiding" the model through tasks it could figure out itself. That's what we got wrong. We used MCP to deliver recipes when we should have used it to provide ingredients.
Skills are portable building blocks
Skills aren't an MCP feature. They're self-contained packages (instructions, code, scripts, examples) that any model can invoke. And as of recently, they're a standard.
The key difference: skills are portable, MCP is connected.
A skill bundles everything needed to accomplish a task. How to build a parser, the code templates, the validation scripts, the examples. It travels with the model, works in Claude Code, works offline, works anywhere a model can read and execute.
MCP connects to running infrastructure. It can't be bundled. It requires authentication, state, network access. That's its strength for distributed orchestration, and its weakness for portable workflows.
We made the mistake of encoding portable knowledge into connected tools. Skills encode what to do and how to do it. MCP provides access to external systems that skills can't bundle. When we conflated the two, we built orchestration tools that burned tokens re-explaining workflows the model could figure out itself.
The offline advantage
Skills are portable, but they still need something to connect to.
In our Claude Code setup, skills invoke shell commands that talk to a Tenzir node, fetch docs from the web, validate against online schemas. The skill travels; the infrastructure doesn't.
For air-gapped environments, classified networks, and on-prem deployments, that infrastructure needs to be local. That's where MCP earns its keep: connecting local models to local Tenzir nodes, with bundled docs and schemas that don't require network access.
Our MCP server serves customers who:
Can't send data to external APIs (regulatory, compliance, security)
Run local models on their own hardware
Operate in environments where "cloud" is a four-letter word
The MCP server becomes what it should have been: a connection layer, not a workflow engine. Skills handle the portable parts—instructions, code, templates, validation logic. MCP handles the connected parts—talking to infrastructure that skills can't bundle.
The lesson
Abstraction isn't always value. Sometimes it's just cost. But you don't know which until you measure.
For cloud-connected workflows with frontier models, our MCP tools were expensive indirection. The model didn't need our orchestration, it needed capabilities and documentation.
For offline deployments with local models, the same tools provide genuine value. Bundled docs, sandboxed execution, and structured interfaces matter when you can't just "curl the internet."
MCP isn't wrong. What's wrong is building without measuring, or measuring without adapting. We built for one deployment model, measured against another, and learned something. Now we're shipping the fix.
The real lesson: iterate faster than your assumptions age. In AI tooling, that means weekly.
The refocused MCP server ships next quarter. We're already running the Skills approach internally—the entire team uses our Claude Marketplace daily for workflow knowledge, while MCP handles what it's good at: external capabilities.
If you're using our MCP server today, nothing breaks. If you're a Claude Code user, check out the Tenzir Claude Marketplace, it's what we use. If you're running local models in air-gapped environments, the MCP server remains your path to Tenzir's capabilities, now without the workflow overhead.
Move fast. Measure everything. Adapt when the data tells you to. That's the game.